
RP1 - Computing-in-Memory Architecture for Large-scale AI Models
RP1 Tackling the compute, memory, and memory bandwidth scaling problems, particularly focusing on advancing CIM-based chip architecture to enable the ultra-energy-efficient and scalable deployment of large-scale AI models.
RP1-1:
Hybrid ReRAM-SRAM-based Computing-in-Memory AI Processor for Large Language Models
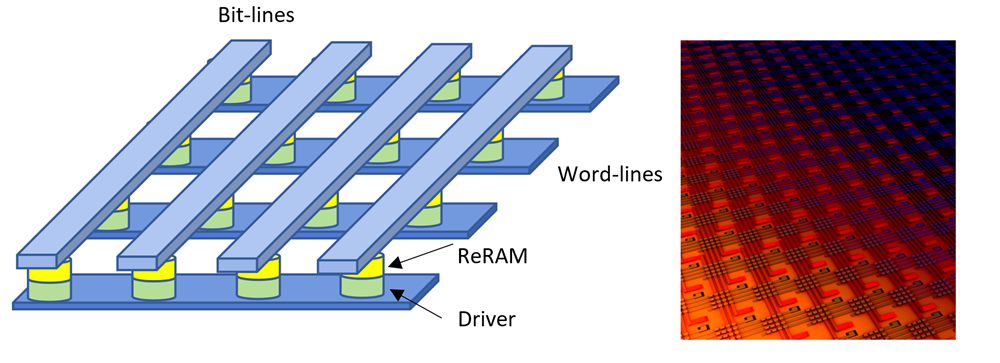
Figure RP1-1 Hybrid CIM AI processor. (a) Conventional ReRAM memory. (b) Hybrid ReRAM-SRAM CIM cell. (c) Hybrid CIM-based processor architecture.
This project aims to design a hybrid CIM AI processor that leverages the advantages of both ReRAM and SRAM technologies. ReRAM offers benefits such as non-volatility and small footprint but faces challenges as in expensive conversions and resistance variability. SRAM, while mature and reliable, is large and requires significant data movement. By integrating ReRAM and SRAM into a single compute-memory cell, this project aims to create a high-performance, high-efficiency processor for large-scale AI model inference. The hybrid design will involve transistor-level design, hierarchical segmented arrays, and a fully-on-chip memory system, ensuring reliable and accurate MAC operations while reducing latency and energy consumption.
RP1-2:
Computing-in-Memory Enabled On-Device Large Language Model Personalization
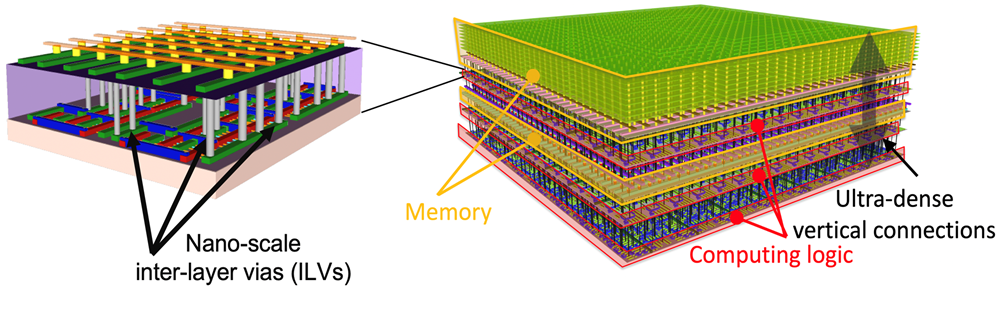
Figure RP1-2 On-device learning of large-scale models with algorithm-CIM hardware co-design.
This project addresses the privacy and trust concerns associated with centralized cloud-based LLMs and LVLMs by enabling on-device personalization with CIM. Deploying these models on edge devices allows for personalized responses while keeping private data local. The project will explore techniques such as model compression, quantization, and data selection to adapt large-scale models for edge devices. Additionally, it will focus on accelerating and optimizing these models to reduce latency and training costs. By developing data refinement methods and self-learning frameworks, the aim is to enhance the personalization capabilities of edge-based models, creating a guidebook for future development.
RP1-3:
Reconfigurable Computing-in-Memory Architecture on 3D Non-Volatile Memory Technology
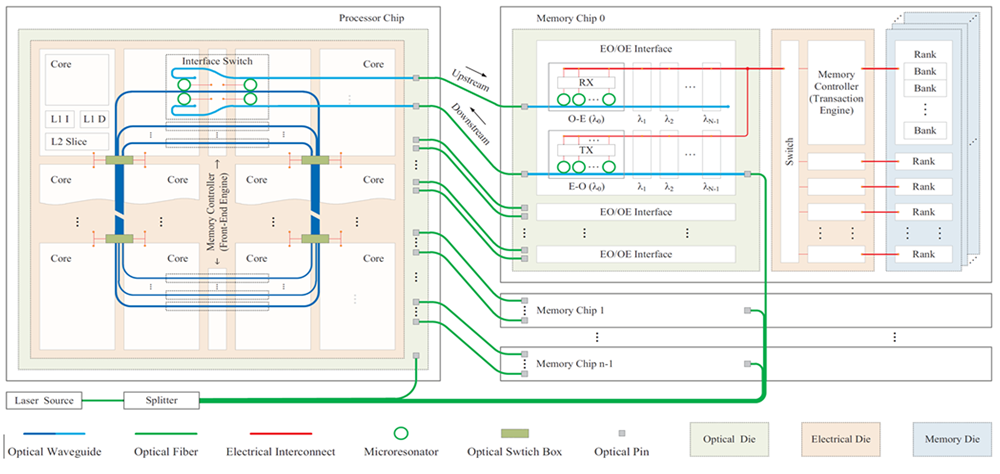
Figure RP1-3 Reconfigurable CIM based on 3D NVM. (a) 3D NAND FeFET memory and 3D FeFET crossbar array. (b) Reconfigurable CIM architecture.
This project aims to overcome the limitations of current CIM chips by developing reconfigurable CIM architectures using 3D non-volatile memory (NVM) technologies such as ferroelectric memory. These technologies offer higher memory bandwidth, lower write voltages, faster write speeds, and improved endurance, enhancing CIM performance and efficiency. The project will focus on creating a reconfigurable CIM architecture that can handle multiple data operations, such as parallel search and matrix multiplication, by re-imagining the use of NVM kernels and dynamic interconnections. This approach aims to accelerate a diverse array of AI computational tasks, unlocking the full potential of CIM technology.
RP1-4:
Memory-Centric Heterogenous Processor for Large-scale AI Models

Figure RP1-4 Memory-centric heterogeneous architecture with DRAM-based PnM and PuM.
This project will alleviate the data movement bottleneck that limits the efficiency and performance of modern computing systems. By shifting from a processor-centric design to a data-centric design, where processing elements are placed closer to the data, the project will explore Near-Data Processing (NDP) and Processing-in-Memory (PIM) architectures. These architectures will combine Processing-near-Memory (PnM) and Processing-using-Memory (PuM) approaches to maximize benefits. The goal is to significantly accelerate large-scale AI models and other data-intensive workloads, improving performance, energy efficiency, and scalability in a manner that can be easily used by various programmers and system designers.