
RP2 - Hardware-Software Co-Design for Energy-Efficient and High-Performance Edge AI
Advancing the field of algorithm-hardware co-design, addressing new challenges arising from the increasing complexity, scalability, energy efficiency, and latency requirements of embodied large-scale AI applications.
RP2-1:
Hardware/Software Co-Optimization Toward Energy-Minimal Personalized Health-AI Companions
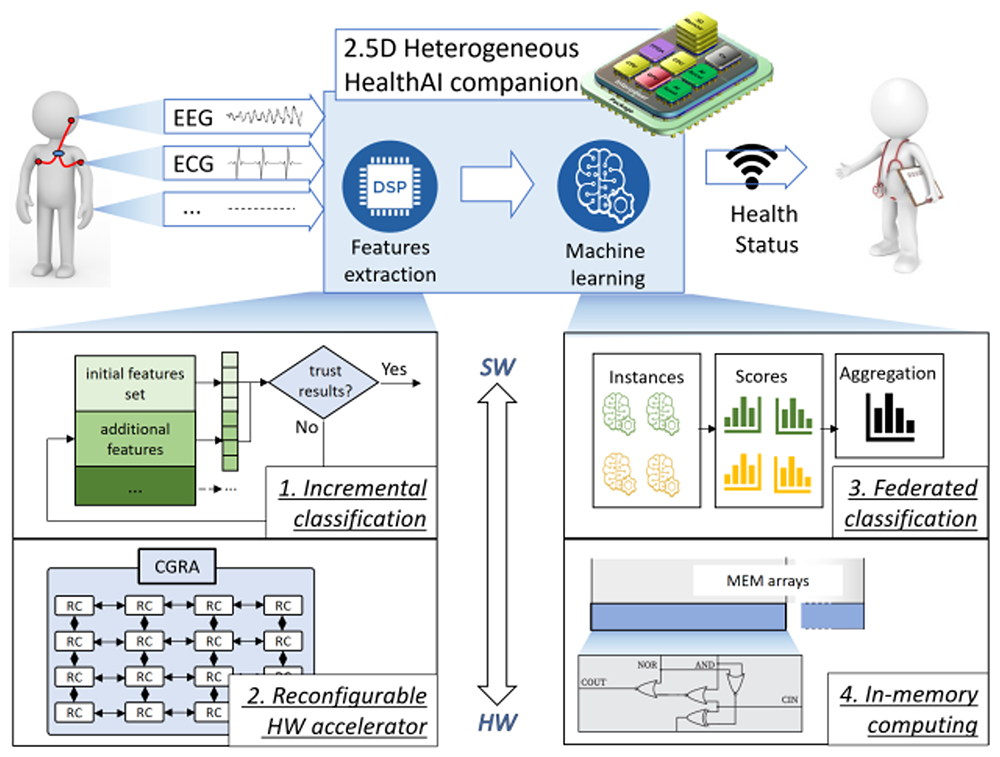
This project aims to create ultra-low-power AI companions for chronic health condition monitoring. It focuses on co-optimizing feature extraction and machine learning algorithms to meet the strict energy and performance requirements of edge devices. Novel strategies for in-memory and near-memory computing will be developed to minimize energy consumption while ensuring high-quality real-time processing of bio-signals.
RP2-2:
Energy Efficient Heterogeneous Edge-Cloud Collaborative Learning Paradigm for Large-Scale AI Models with Privacy Preservation
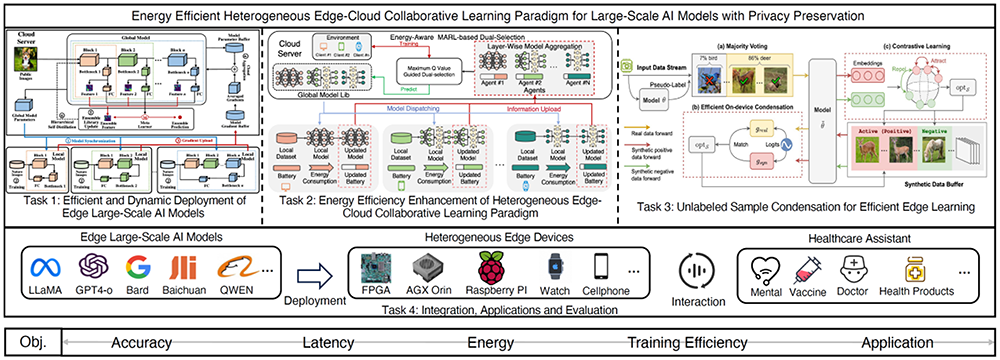
This project addresses the challenge of deploying large-scale AI models on resource-constrained edge devices without compromising performance or privacy. By leveraging a heterogeneous framework for hardware and neural architecture co-exploration, this project aims to enable efficient and dynamic deployment of large-scale AI models. Additionally, an energy-aware cloud-edge collaborative learning paradigm will be developed to optimize energy consumption and enhance learning efficiency, particularly in federated learning scenarios.
RP2-3:
A Hardware-aware Software Optimization of 3D Neural Rendering Algorithms for Real-time Acceleration in Edge Devices
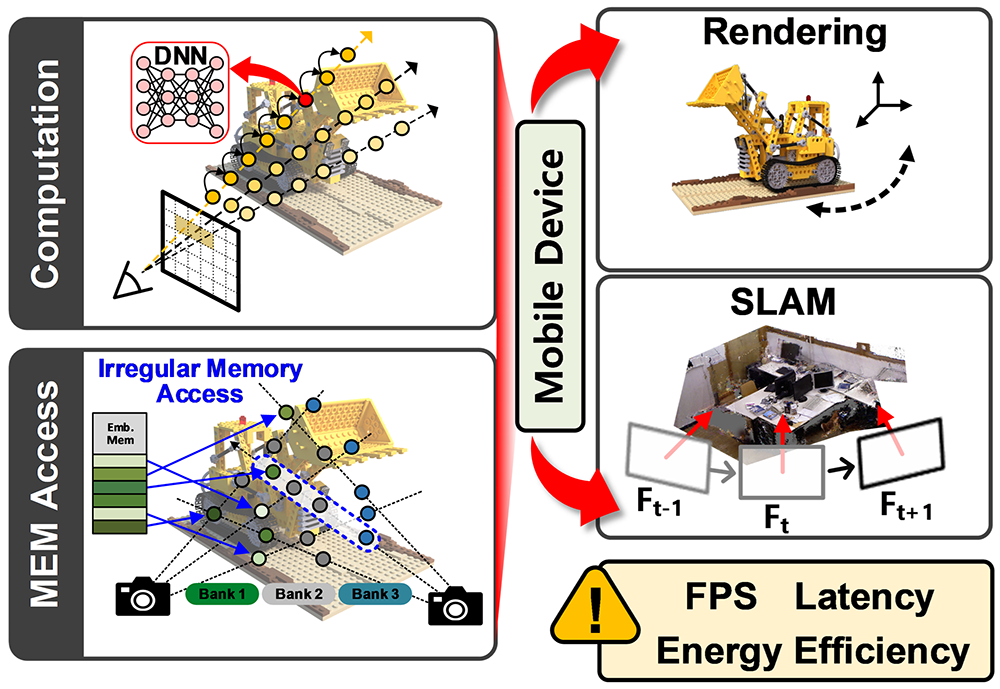
This project targets the optimization of recent Neural Radiance Field (NeRF) algorithms for mobile rendering and simultaneous localization and mapping (SLAM). To address the intrinsic high computational and power overhead, this project proposes a hardware-aware software co-design, optimizing data representation, hierarchical volume sampling, and reusable pixel determination for rendering, thereby achieving significant improvements in latency and energy efficiency.
RP2-4:
Energy-efficient Inference and Fine-tuning of Diffusion Transformers using Dynamic Mixed-precision Arithmetic for Generative AI
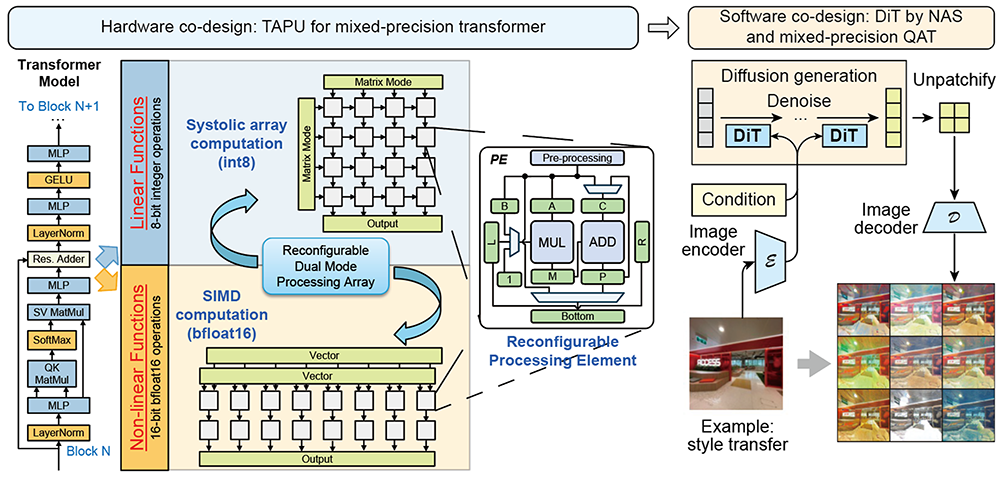
This project tackles the challenges associated with Transformer-based large-scale AI models by developing a mixed-datatype accelerator that supports both integer and floating-point operations, facilitating efficient inference and model fine-tuning on edge devices. The co-design of hardware and software for style transfer applications will demonstrate the practical benefits of this approach.